
Accurate Prediction of Virus-Host Protein-Protein Interactions via a Siamese Neural Network Using Deep Protein Sequence Embeddings
By Sumit Madan, Victoria Demina, Marcus Stapf, Oliver Ernst, and Holger Froehlich
Excerpt from the preprint article published in bioRxiv 2022.05.31.494170; DOI: https://doi.org/10.1101/2022.05.31.494170
Editor’s Highlights
- Prediction and understanding of tissue-specific virus-host interactions have relevance for the development of novel therapeutic intervention strategies.
- A novel deep learning approach to predict virus-host protein-protein interactions (PPIs), is the method (Siamese Tailored deep sequence Embedding of Proteins – STEP) based on recent deep protein sequence embedding techniques
- For the SARS-Cov-2 spike protein, our model interestingly predicted for all virus variants an interaction with the sigma intracellular receptor 2 (sigma-2 receptor/TMEM97), which might explain the cytopathic effects of sigma receptor binding ligands.
- The antiviral effect observed in cell lines treated with sigma receptor binding ligands might be due to a modulated binding of the spike protein, hence inhibiting virus entry into cells.
The bigger picture
Development of novel cell and tissue specific therapies requires a profound knowledge about protein-protein interactions (PPIs). Identifying these PPIs with experimental approaches such as biochemical assays or yeast two-hybrid screens is cumbersome, costly, and at the same time difficult to scale. Computational approaches can help to prioritize huge amounts of possible PPIs by learning from biological sequences plus already-known PPIs. In this work, we developed a novel approach (Siamese Tailored deep sequence Embedding of Proteins – STEP) that is based on recent deep protein sequence embedding techniques, which we integrate into a Siamese neural network architecture. We use this approach to train models by utilizing protein sequence information and known PPIs. After evaluating the high prediction performance of STEP in comparison to an existing method, we apply it to two use cases, SARS-CoV-2 and John Cunningham polyomavirus (JCV), to predict virus protein to human host interactions. Altogether our work highlights the potential of deep sequence embedding techniques originating from the field of natural language processing as well as Explainable AI methods for the analysis of biological sequence data.
Authors’ Highlights
- A novel deep learning approach (STEP) predicts virus protein to human host protein interactions based on recent deep protein sequence embedding and a Siamese neural network architecture
- Prediction of protein-protein interactions of the JCV VP1 protein and of the SARS-CoV-2 spike protein
- Identification of parts of sequences that most likely contribute to the protein-protein interaction using Explainable AI (XAI) techniques
Abstract
Prediction and understanding of tissue-specific virus-host interactions have relevance for the development of novel therapeutic interventions strategies. In addition, virus-like particles (VLPs) open novel opportunities to deliver therapeutic compounds to targeted cell types and tissues. Given our incomplete knowledge of virus-host interactions on one hand and the cost and time associated with experimental procedures on the other, we here propose a novel deep learning approach to predict virus-host protein-protein interactions (PPIs). Our method (Siamese Tailored deep sequence Embedding of Proteins – STEP) is based on recent deep protein sequence embedding techniques, which we integrate into a Siamese neural network architecture. After evaluating the high prediction performance of STEP in comparison to an existing method, we apply it to two use cases, SARS-CoV-2 and John Cunningham polyomavirus (JCV), to predict virus protein to human host interactions. For the SARS-CoV-2 spike protein our method predicts an interaction with the sigma 2 receptor, which has been suggested as a drug target. As a second use case, we apply STEP to predict interactions of the JCV VP1 protein showing an enrichment of PPIs with neurotransmitters, which are known to function as an entry point of the virus into glial brain cells. In both cases we demonstrate how recent techniques from the field of Explainable AI (XAI) can be employed to identify those parts of a pair of sequences, which most likely contribute to the protein-protein interaction. Altogether, our work highlights the potential of deep sequence embedding techniques originating from the field of natural language processing and XAI methods for analyzing biological sequences. We have made our method publicly available via GitHub.
Introduction
Viral infections can cause severe tissue-specific damages to human health. In case of the infection of brain cells severe neurological disorders can be the consequence (Swanson et al. 2015). Accordingly, prediction and understanding of tissue-specific virus-host interactions is important for designing targeted therapeutic intervention strategies. At the same time virus-like particles (VLPs), such as John Cunningham VLPs, open novel opportunities to deliver therapeutic compounds to targeted brain cells and tissues, because these proteins have the ability to cross the blood-brain barrier (Ye et al. 2021). Hence, it is also relevant from a therapeutic perspective to know the binding of VLPs to potential drug receptors in the brain.
The knowledge about virus-host interactions covered in databases like VirHostNet (Guirimand et al. 2015) is limited. While various experimental approaches exist to measure protein-protein interactions (PPI), including yeast two-hybrid screens, biochemical assays, and chromatography (Lalonde et al. 2008), these methods are often time consuming, laborious, costly, and difficult to scale to large numbers of possible PPIs. Thus, computational methods have been proposed that use various types of protein information to predict PPIs. Older approaches focused on predicting PPIs either using structure and/or genomic context of proteins (Skrabanek et al. 2008). Other approaches (Shen et al. 2007, Zhou et al. 2018) suggested classical machine learning algorithms (such as support vector machines) in combination with manually engineered features derived from protein sequences to predict PPIs.
In recent years, deep learning-based approaches (Sun et al. 2017, Wang et al. 2017, Xu et al., 2020, Tsukiyama et al., 2021) have become popular and have increasingly superseded traditional machine learning approaches for the prediction of PPIs. Often these approaches use known PPIs from established PPI databases (e.g., BioGrid, IntAct, STRING, HPRD, VirHostNet – Oughtred et al. 2020, Orchard et al. 2014, Szklarczyk et al. 2018, Keshava Prasad et al. 2009, Guirimand et al. 2015) to generate datasets to train deep neural network architectures. Some of these methods employ recent network representation learning techniques to complete a known virus-host protein-protein interaction graph (Du et al., 2021). Other authors focused on protein sequences to predict PPIs. For example, Sun et al. (2017) and Wang et al. (2017) proposed to employ a stacked autoencoder (SAE). Chen et al. (2019) developed a deep learning framework employing a Siamese neural architecture to predict binary and multi-class PPIs. Tsukiyama et al. (2021) recently proposed an LSTM-based model on top of a classical word2vec embedding of sequences to predict human-virus PPIs by using protein sequences. Using the same embedding technique, Liu-Wei et al. (2021) developed an approach, which predicts host-virus protein-protein interactions for multiple viruses considering their taxonomic relationships.
In the last few years, transfer learning-based approaches from the natural language processing (NLP) area have massively impacted the field of protein bioinformatics (Elnaggar et al. 2021; Min et al. 2019; Heinzinger et al. 2019). These methods are trained on a huge amount of protein sequences to learn informative features of protein sequences. For instance, Elnaggar et al. (2021) employed 2.1 billion protein sequences for the pre-training of ProtTrans, a collection of transformer models originally stemming from the NLP field. Such
methods allow the transformation of a protein sequence into a vector representation, which can subsequently be used efficiently for various downstream tasks, e.g. protein family classification (Nambiar et al. 2020). There are several advantages of using the available pre-trained transformer models, such as avoiding the error-prone design of hand-crafted features to encode protein sequences and correspondingly a much more efficient development of new AI models with potentially higher prediction performance.
In this paper, we introduce a novel deep learning architecture combining the recently published ProtBERT (Elnaggar et al. 2021) deep sequence embedding approach with a Siamese neural network to predict PPIs by utilizing the primary sequences of protein pairs. While recent publications generally follow a similar strategy, they have employed more traditional sequence embedding methods (Tsukiyama et al. 2021). To our knowledge, our work thus constitutes the first attempt to evaluate the usage of most recent, pre-trained transformer models to obtain a deep learning-based biological sequence embedding for PPI prediction. After evaluating the promising prediction performance of our method (Siamese Tailored deep sequence Embedding of Proteins – STEP), we employ it for two use cases: i) predicting interactions of the John Cunningham polyomavirus (JCV) major capsid protein VP1 (UniProt:P03089) with human receptors in the brain, and ii) predicting interactions of the SARS-CoV-2 spike glycoprotein (UniProt:P0DTC2) with human receptors. Predicted interactions in both cases demonstrate a clear interpretation in the light of existing literature knowledge, hence supporting the biological relevance of predictions made by our method.
With this study, we make four contributions to the state-of-the-art. Firstly, we construct a novel deep learning architecture STEP for virus-host PPI prediction that requires only the protein sequences as the input and discards the need of handcrafted or other types of features. Secondly, we demonstrate that utilizing transformer-based models for PPI prediction achieves at least state-of-the-art performance for PPI prediction. In computer vision and NLP, such transformer-based models have shown that they are well suited for learning contextual relationships hidden in sequential data. However, these have not yet been applied to the field of PPI prediction. Hence, we use and build on the huge effort of Elnaggar et al. (2021), who published a pre-trained ProtBERT model that was trained on over two billion amino acid sequences. In addition, we demonstrate that using transfer learning in STEP achieves state-of-the-art performance, for which we evaluated STEP on multiple publicly-available virus-host and host-host PPI datasets. Thirdly, we predict interactions for two viruses that are known to cause serious diseases and provide an interpretation on those predictions demonstrating the support through existing literature knowledge. Lastly, we show how experimental XAI techniques could be used to identify regions in protein amino acid sequences that attribute to the prediction of protein-protein interaction.
Results
Comparative Evaluation of STEP with State-of-the-art Work
We performed a head-to-head comparison of our STEP architecture on three different datasets published by Tsukiyama et al. (2021), Guo et al. (2008), and Sun et al. (2017). Tsukiyama et al. (2021) recently published the LSTM-PHV Siamese model, which employs a more traditional word2vec sequence embedding. The dataset published by the authors consists of host-virus PPIs that were retrieved through the Host-Pathogen Interaction Database 3.0 (Ammari et al. 2016). In total, the dataset consists of 22,383 PPIs with 5,882 human and 996 virus proteins. Additionally, it includes artificially sampled negative instances with the positive to negative ratio of 1:10. The authors themselves compared LSTM-PHV on their dataset against a Random Forest approach by Yang et al. (2020). Guo et al. (2008) published a Yeast PPI dataset and used support vector machines to build a PPI detection model. Sun et al. (2017) created a dataset using human protein references database (HPRD), which contains human-human PPIs. Tsukiyama et al. (2021) and Guo et al. (2008) performed a 5-fold cross validation (CV) experiment, whereas Sun et al. (2017) used a 10-fold CV setting. We evaluated our STEP architecture using the exact same datasets with the exact same data splits as the authors of the compared methods. STEP was initialized with the hyperparameters shown in Table S1). Table 1 shows the results of all experiments, demonstrating at least state-of-the-art performance of our method. Additionally, we can conclude that our approach compared on exactly the same data published by Tsukiyama et al. (2021) performs similar to their LSTM-PHV method and better than the approach by Yang et al (2020).
Finally, we also evaluated our STEP architecture on two additional tasks, namely PPI type prediction and a PPI binding affinity estimation using the data by Chen et al. (2019). For both tasks, we reached at least state-of-the-art performances with our approach (see Supplementary Material; Table S4).
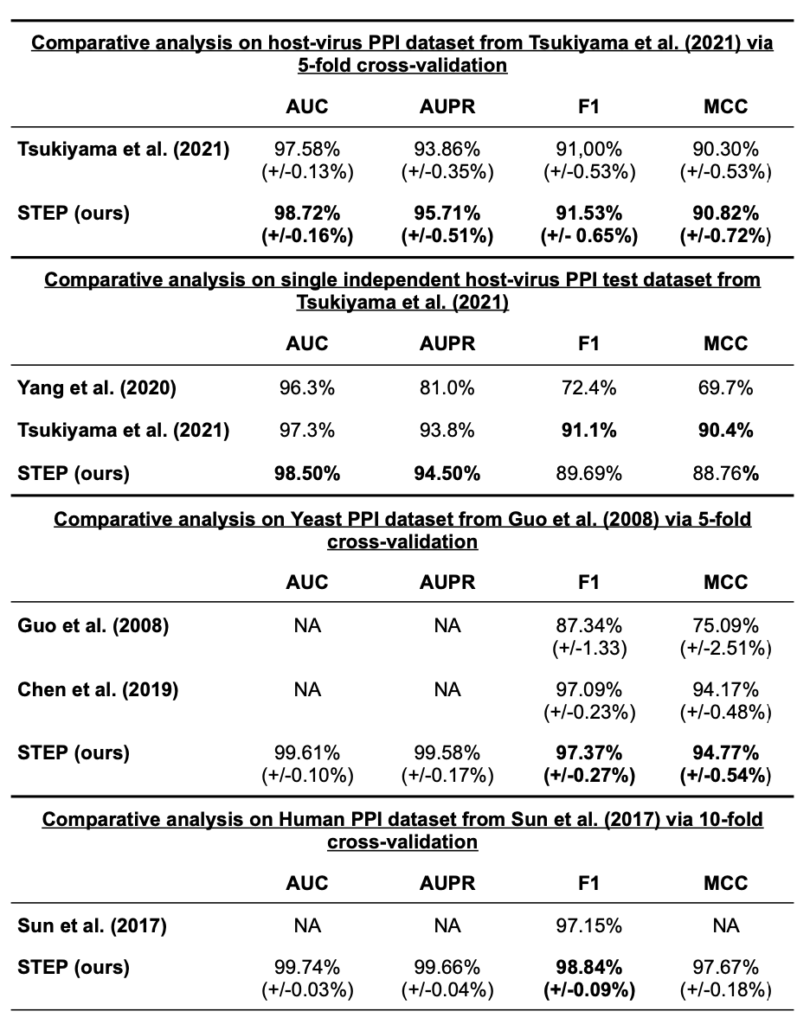
Overview of the results of comparative evaluation of STEP on LSTM-PHV (Tsukiyama et al. 2021), Yeast (Guo et al. 2008), and Human PPI (Sun et al. 2017) datasets. For LSTM-PHV and Yeast PPI datasets, we applied a 5-fold cross validation similar to the authors of the given studies. For the Human PPI dataset of Sun et al. (2017), we applied a 10-fold cross validation for training the STEP models. The highest values are highlighted in bold. More details of each experiment can be found in Supplementary Tables S1, S2, and S3. NA = not available in original publication.
Prediction of JCV Major Capsid Protein VP1 Interactions
We split the brain tissue-specific interactome dataset including all positive and pseudo-negative interactions into training (60%), validation (20%), and test (20%) datasets. The validation set was used for tuning hyper-parameters of the model only (see Table S5). After tuning on the validation set, we used our best model to make predictions on the hold-out test set. Figure 2 illustrates the area under receiver operator characteristic curve (AUC) and Precision-Recall Curve (AUPR). The model achieved an AUC and AUPR of 88.78% and 88.32% on the unseen test set, respectively. Also on an extended test set with a ratio 1:10 of positive to pseudo-negative samples the results are quite stable (see Table S6).
We used this STEP-Brain model to predict interactions of the JCV major capsid protein VP1 with all human receptors. Table 2 shows the top 10 predicted interactions that are ranked by the score retrieved by the logistic output function of the model. Supplementary File S3 contains all the predicted interactions. According to the method of integrated gradients, large parts of the VP1 sequence contribute to our model’s prediction of the protein-protein interaction with the top ranked receptor KIAA1549 (Figure S4). More specifically, signal peptide N-regions in KIAA1549 negatively contribute to the predicted class, whereas the beginning of the non-cytoplasmic domain region is contributing positively.
Altogether, we observed a strong enrichment of VP1 interactions predicted with olfactory, serotonin, amine, taste, and acetylcholine receptors (Figure S2). Notably, neurotransmitter (and specifically serotonin) receptors have previously been suggested to be the entry of the virus into myelin producing glial brain cells (Ferenczy et al. 2012), causing progressive multifocal leukoencephalopathy as a fastly progressing and life-threatening neurodegenerative disorder (Boothpur and Brennan 2010). Furthermore, we found an enrichment of tyrosine kinase activity, which is in line with the fact that tyrosine kinase inhibitors have been suggested as therapy against JCV (Querbes et al. 2004, Bennet et al. 2018).
We further performed an enrichment analysis with InterPro (Blum et al. 2021) protein domains for the predicted interactions between JCV major capsid protein VP1 and human receptors (Figure S5, Table S7). In line with the GO enrichment analysis, the two top-ranked protein domains InterPro:IPR006029 and InterPro:IPR006202 are neurotransmitter-gated ion channel transmembrane domains that open transiently upon binding of specific ligands, which then allow transmission of signals at chemical synapses (Kofuji et al. 1991, Wagner et al. 1991). Furthermore, the receptor-type tyrosine-protein phosphatase / carbonic anhydrase domain is enriched, which is in line with the enrichment of tyrosine kinase activity found via GO analysis. The enriched domains InterPro:IPR013106 (Immunoglobulin V-set domain) and InterPro:IPR007110 (Immunoglobulin-like domain) are both immunoglobulin-like domains that are involved in cell-cell recognition, cell-surface receptors and immune system response (Teichman et al. 2000), which play a role in the recognition of a virus protein.
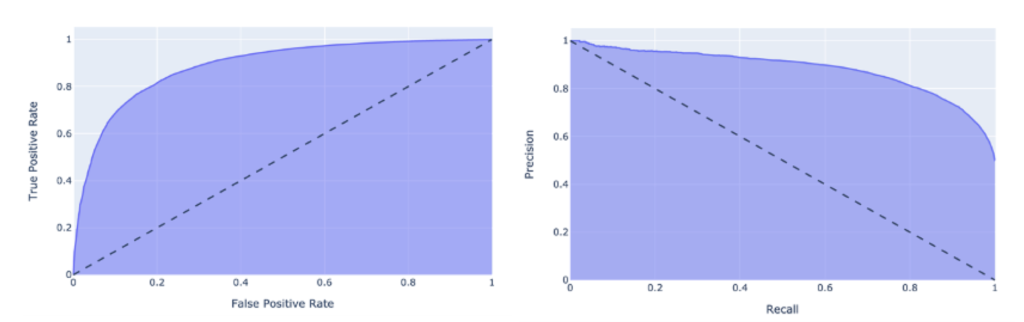
Receiver Operator Characteristic (ROC) curve (left) and precision-recall curve (right) obtained by applying the STEP-Brain model on unseen test data.
Prediction of SARS-CoV-2 Spike Glycoprotein Interactions
We performed a nested cross-validation procedure on the given SARS-CoV-2 interactions dataset. We used 5 outer and 5 inner loops to validate the generalization performance and while performing the hyperparameter optimization in the inner loop. In each outer run, we created a stratified split of the interactome into train (4/5) and test (1/5) datasets. In the nested run, we further split the outer train dataset into train (1/5) and validation (1/5) datasets, which were used to optimize the hyperparameters of the model using the respective training data. The performance of the classifiers was evaluated with AUC and was averaged over all nested runs. The best identified hyperparameters (see Table S8) were used to train the models in the outer loop. We retrieved a final generalization performance of 83.42% (+/- 3.91%) AUC and 84.02% (+/- 4.58%) AUPR that was calculated by averaging the prediction results of the outer loop (see Table 3).
We used the STEP-Virus-Host model obtained from the best outer fold to predict interactions of the SARS-CoV-2 spike protein (alpha, delta and omicron variants) with all human receptors, which were not already contained in VirHostNet (see Supplementary Table S11, S12, S13). Supplementary File S4 contains all the predicted interactions for the omicron variant. Interestingly, for all virus variants the sigma intracellular receptor 2 (GeneCards:TMEM97; UniProt:Q5BJF2) was the only one predicted with an outstanding high probability (of >70% in all cases, Tables S11 – S13). Sigma 1 and 2 receptors are thought to play a role in regulating cell survival, morphology, and differentiation (Huang et al. 2014, Guo and Zhen 2015). In addition, sigma receptors have been proposed to be involved in the neuronal transmission of SARS-CoV-2 (Yesilkaya et al. 2020). They have been suggested as a target for therapeutic intervention (Abate et al. 2020, Gordon et al. 2020, Ostrov et al. 2021). Our results suggest that the observed antiviral effect observed in cell lines treated with sigma receptor binding ligands might be due to a modulated binding of the spike protein, hence inhibiting virus entry into cells. In this context an analysis via the integrated gradients method shows that only parts of the sigma 2 receptor and the SARS-CoV-2 spike protein contribute to our model’s prediction of the protein-protein interaction (Figure S6). More specifically, the non-cytoplasmic domain and EXPERA domains demonstrate positive integrated gradient scores, i.e. the existence of these domains influence our model to make the according prediction.
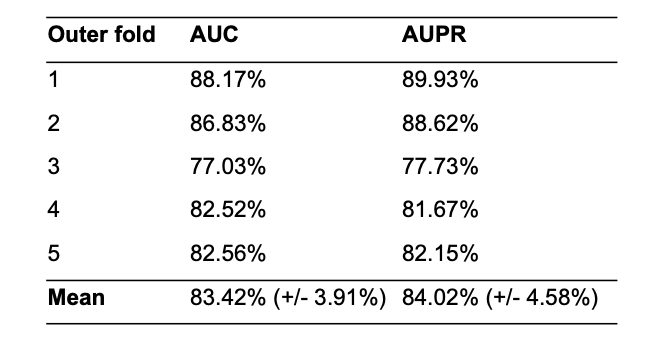
Results of the outer loop folds retrieved during the nested cross validation of STEP-Virus-Host model by using the test set with a ratio of 1:1 positive to pseudo-negative instances.
Conclusion
Huge advancements have been made recently by applying deep learning algorithms from the natural language processing field to protein bioinformatics. Protein language models such as ProtTrans and ProtBERT (Elnaggar et al. 2021) trained on billions of protein sequences learn informative features through the transformation of sequences to vector representations. These models previously showed their predictive power in various tasks such as prediction of secondary structure or classification of membrane proteins (Elnaggar et al. 2021).
In our work, we used ProtBERT within a specifically designed Siamese neural network architecture to predict PPIs by only utilizing the primary sequences of protein pairs. We trained our models following a PU learning scheme and performed an extensive evaluation and hyperparameter optimization of our models, demonstrating high prediction performances for virus protein to human receptor interactions of JCV and SARS-CoV-2. An additional head to head comparison to the recently-published method by Tsukiyama et al. (2021) using a more traditional word2vec sequence embedding combined with an LSTM unit revealed state-of-the art prediction performance of our STEP approach.
Interactions predicted by our proposed model between JCV major capsid protein VP1 and receptors in brain cells showed a strong enrichment of different neurotransmitters, including serotonin receptors, which is in line with the current literature. For the SARS-Cov-2 spike protein, our model interestingly predicted for all virus variants an interaction with the sigma intracellular receptor 2, which might explain the cytopathic effects of sigma receptor binding ligands reported in the literature (Abate et al. 2020, Gordon et al. 2020, Ostrov et al. 2021). In both cases recent techniques coming from the field of Explainable AI (XAI) allowed us to interpret model predictions and identify those parts of protein sequences, which according to our model mostly influence the prediction of respective protein-protein interactions. Of course, a validation of these predictions would require experimental procedures, which are beyond the scope of this paper.
Altogether, our work demonstrates the potential of modern deep learning-based biological sequence embeddings and modern XAI techniques for bioinformatics. While in this paper we focused on John Cunningham polyomavirus and SARS-CoV-2, our proposed model could in future work be easily trained to predict interactions of other viruses as well and thus contribute to the emerging set of computational methods that might help to respond to future epidemic and pandemic situations more effectively. In addition, there is the potential to use our method in the context of modern drug development approaches, which employ virus-like particles to deliver compounds to specific tissues and receptors. We have made our method publically available via github.